GameAIfy offers you an opportunity to train your own models and create your own LoRA using your own set of images.
On Train, you can view a list of LoRA’s that you have trained.
If you wish to create a new LoRA, select “Create Model” to head over to the “Train a Model” page.
Functions
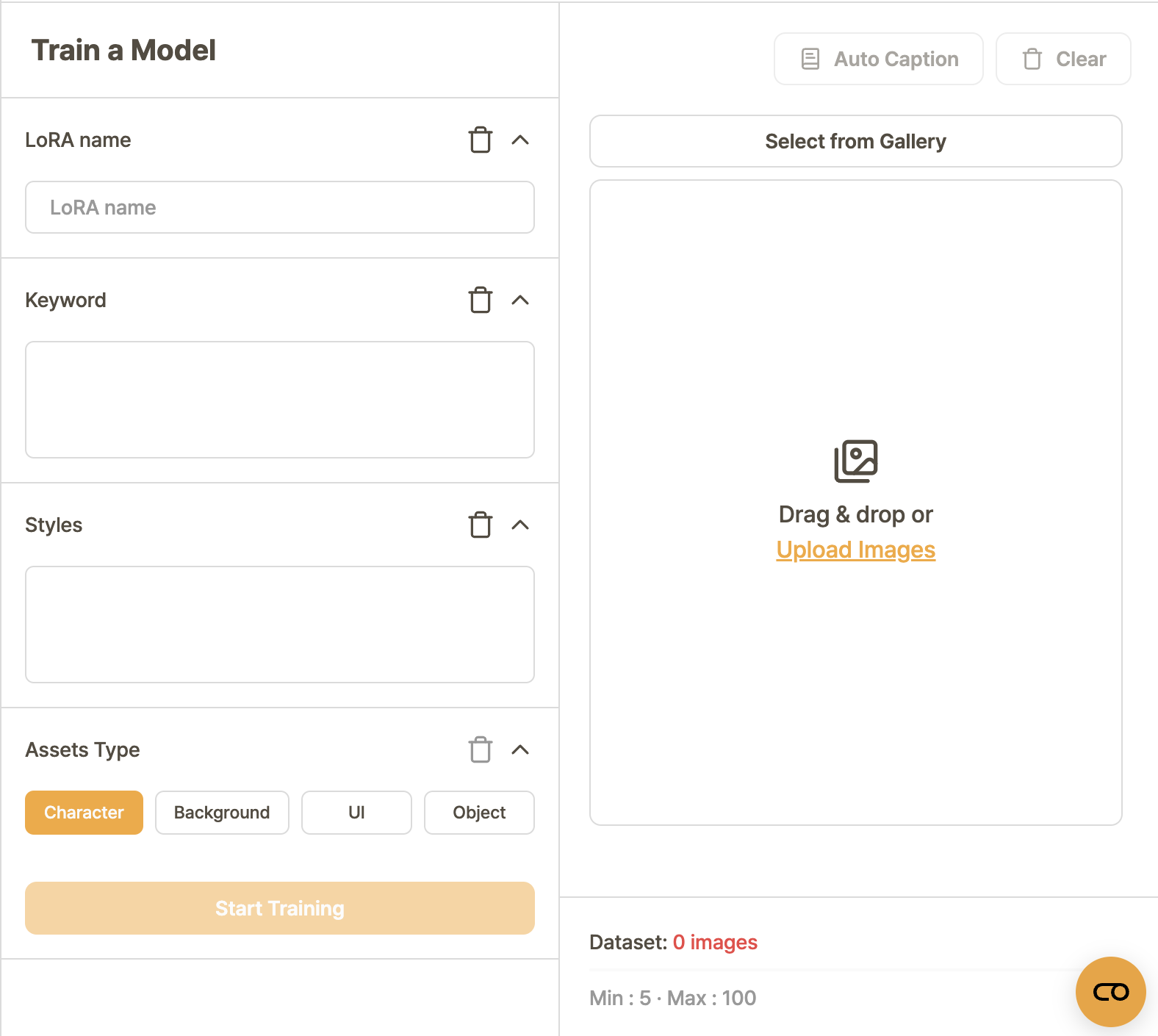
1. LoRA Name
Here you can name the LoRA that you have just completed training.
It is highly advisable that you create distinctive names for each LoRA that create.
2. Keyword
A set of common prompts used to produce images for training.
For example, if you wish to create a LoRA using a specific character, you can use the name of the character as one of the keywords.
3. Styles
A set of common prompts used to produce images for training, this time regarding the illustration style of the image.
You can leave the field blank if needed…
4. Assets Type
Determine which type of asset you want to generate with this LoRA.
Each category is equipped with optimal settings for the category. Knowing which type of asset to create before selecting the asset type will go a long way towards creating optimal outputs.
5A. Select from Gallery
Select images/data from the gallery to be used for training.
(Minimum 5, maximum 30)
5B. Upload Images
Select images/data from your device to be used for training.
(Minimum 5, maximum 30)
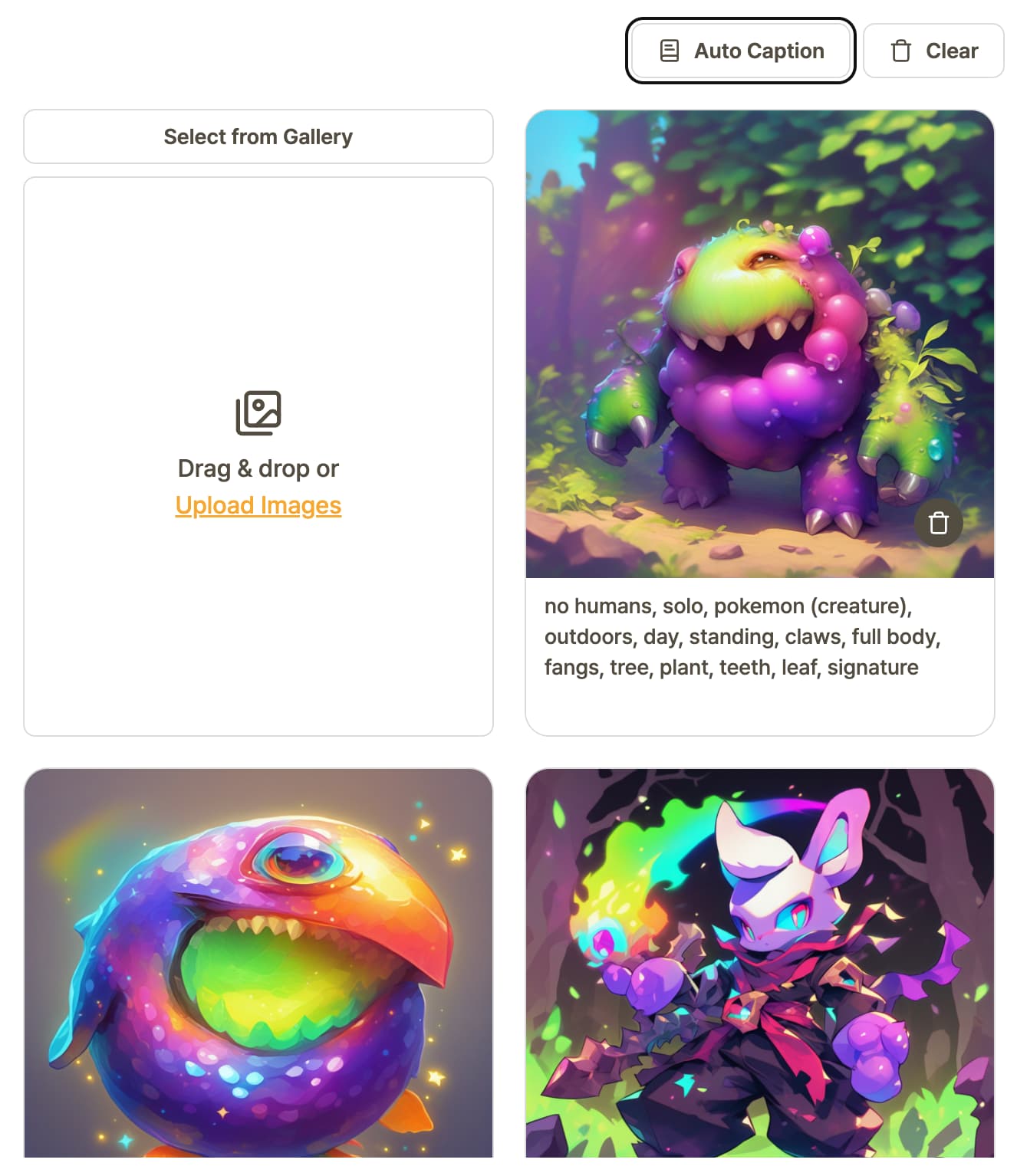
6. Auto Caption
Analyzes trained data to automatically create the most optimal set of prompts for the output.
After the prompts are created, you have a choice of removing prompts that you feel does not contribute to the output.
Pressing “Clear” will delete all trained images that are loaded.
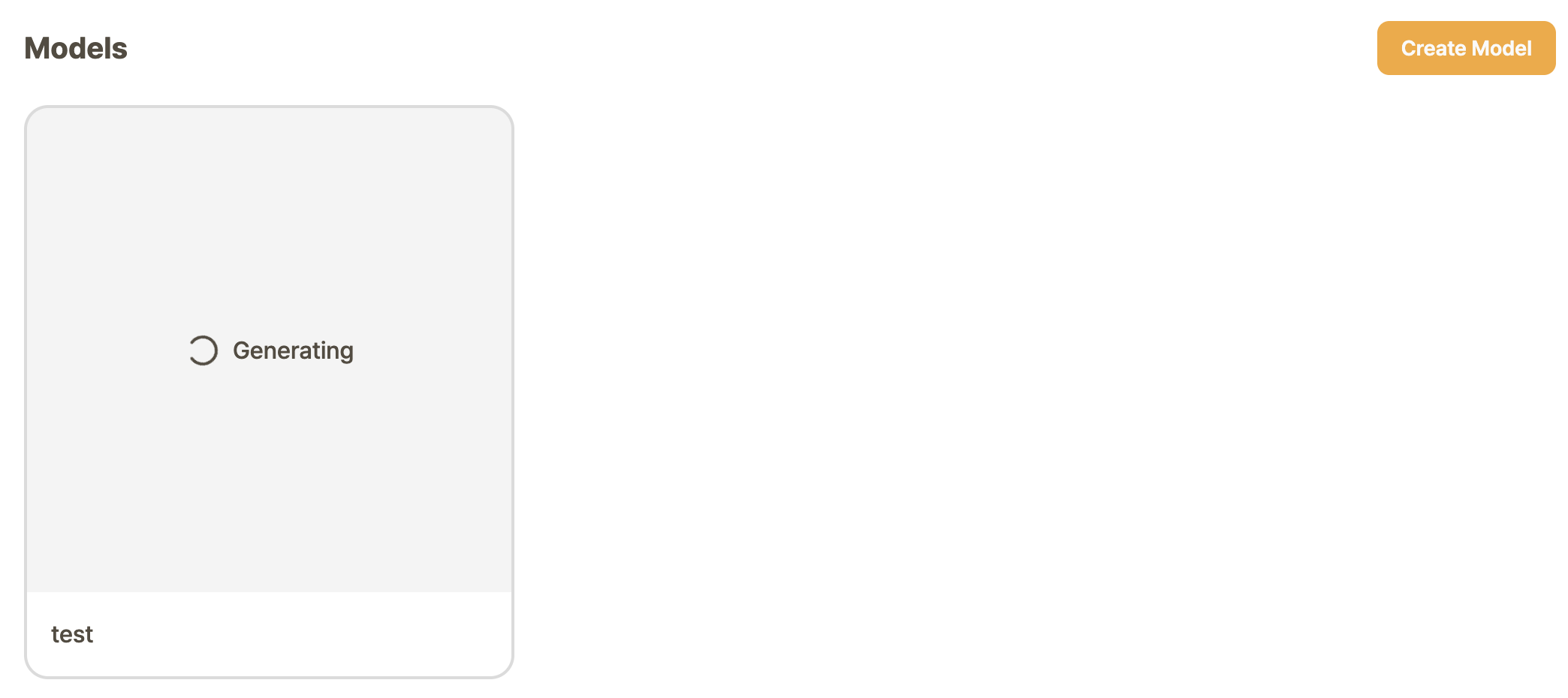
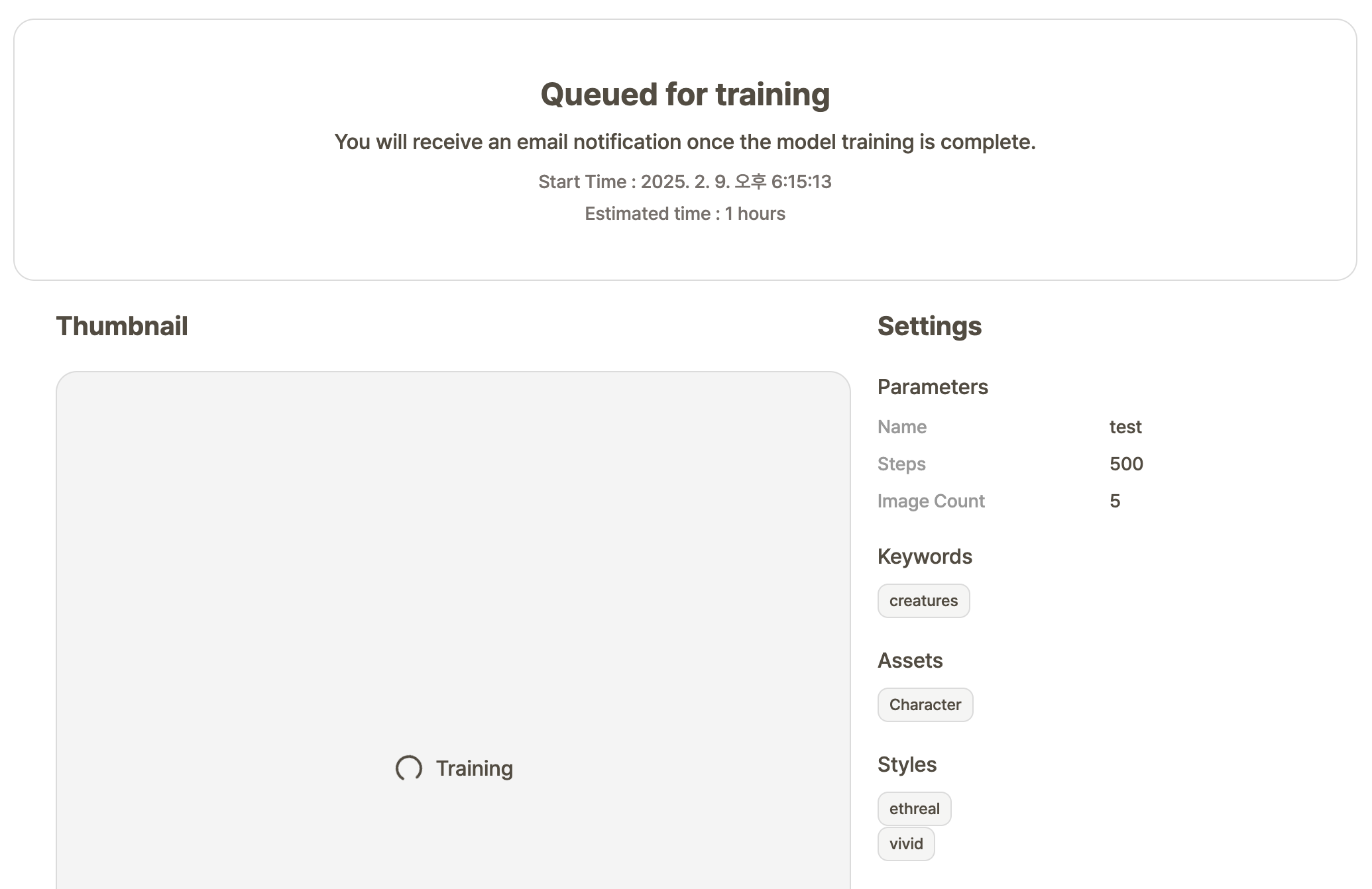
7. Start Training
Once the training begins, you can view the estimated time for completion in the middle of the screen.
Please note that the training still takes place while you are accessing different menus on GameAIfy, so feel free to look around different areas of the website while the model is being trained.
TIPS
- Please note that more data usually means better quality of output, more data also means more training time.
- If the trained image contains multiple duplicates of poses and/or clothes, LoRA could be microtrained to produce a limited range of outputs. Make sure to train your model using a more varied set of images.